In this post I’ll show you how to build your own Linkshortener microservice. If you are still wondering what a microservice is, check out my previous post Microservices! Micro.. what?.
We will be focussed on building a simple REST API that provides the basic functionality we need to create Linkshortener application. If you need to get an idea about what a Linkshortener is, just think about tinyURL or bit.ly where you can submit a long URL and they create a short hash from it. This makes it easier to share a short link with other people instead of the original long URL. When people navigate to this short URL, they will be redirected to the original long URL. The implementation today will be a very simplified version and it will only implement the REST API behind the graphical web interface. In future posts we will be gradually extend this project to highlight other aspects like REST Security, building a frontend with AngularJS, Continuous Delivery with Docker and so on.
Before going any further lets look what operations we want to support in the API. We will be exposing a Links endpoint on URL http://localhost:8080/links and it will support two HTTP methods:
GET: Find all links stored in our databasePOST: Create a new hash based on the URL sent by the user
Besides that we’ll also create an additional endpoint that’s mapped on the root http://localhost:8080/{hash} that will do the actual redirect after we make a request to the original long url. In production we ideally want a very short domain like bit.ly, which is only 6 characters long.
You can find all source code for this blog on my GitHub repository. Feel free to send in pull requests if you see anything that can be improved.
Start building your Linkshortener
As mentioned in the previous post, a microservice needs to handle a specific feature or business requirement. In this case the feature is to shorten links that are too long in size to make them easier to share with others.
In that blog post we also took a quick look at Spring Boot to start an application based on a solid foundation. I will use this today as well, so to start I’ll use the Spring Initializr application to bootstrap the application. We’ll be using two Spring dependencies: Web and Data JPA, which will make sure we will be able to get up and running with Spring Web and Spring Data JPA out of the box. The only thing this does which is visible to us is adding two Spring Boot dependencies to the pom.xml
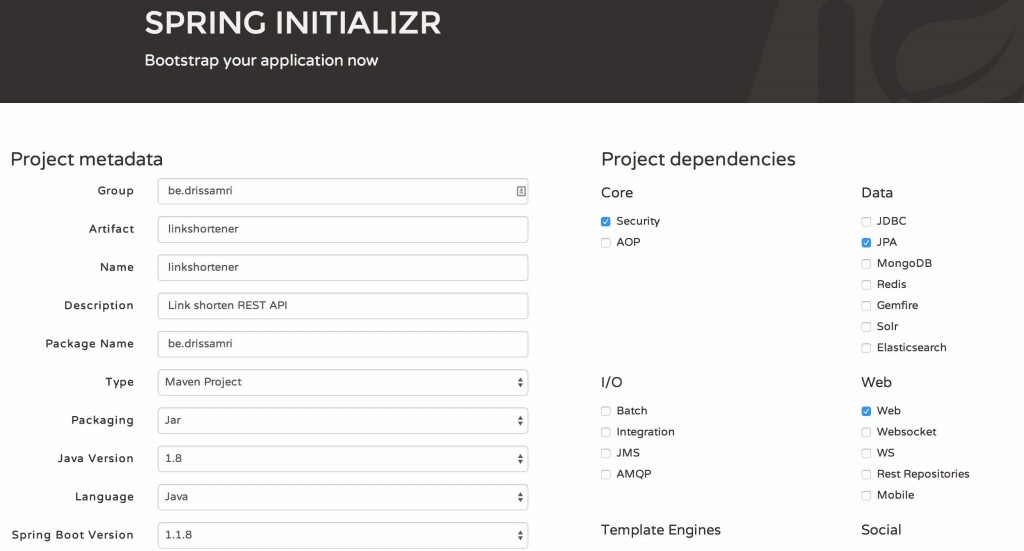
Let’s have a look at the technology we will be using to get started building the API. You’ll notice quite a few testing frameworks since I think it plays an important role in every application. I won’t go into detail in this post, but you’ll find unit and integration tests in the GitHub repository.
- Java 1.8
- Spring Boot, Spring JPA, Spring Web
- HSQLDB: Embedded database
- JUnit, Mockito, AssertJ, RESTAssured
Not all these dependencies can be chosen from the initializr application, so let’s add them other ones to the pom
Database layer: Spring Data JPA and HSQLDB
Let’s start adding a HSQLDB dependency, this will be our embedded database to get started quickly. As soon as you add this dependency, Spring Boot will see this when the context starts up and it will load default configuration for it so we don’t have to do anything at all to get started with it.
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<scope>runtime</scope>
</dependency>
Next up let’s define the JPA Entity that we want to store in the database. I’ll do this by creating a undefined in the undefined package.
@Entity // #1
@Table(name = "LINK")
@EntityListeners({AuditingEntityListener.class}) // #2
public class LinkEntity implements Serializable {
@JsonIgnore
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(name = "url", nullable = false, unique = true)
private String url;
@Column(name = "hash", nullable = false, unique = true)
private String hash;
@JsonIgnore
@CreatedDate // #3
private ZonedDateTime createdDate;
@JsonIgnore
@LastModifiedDate
private ZonedDateTime modifiedDate;
@JsonIgnore
@Version // #4
private long version;#1 We start by defining a JPA entity by using the @Entity and @Table annotations.
#2 We will use the Spring Data JPA’s auditing capabilities to save the date when an entity is created or modified, we add the AuditEntityListener class which will let us annotate date fields as @CreatedDate and @LastModifiedDate and these will be filled in automatically when we persist this entity to the database.
#3 It might be interesting to see, we won’t be using the broken java.util.Date anymore since we are using JDK8 we can use the new Date and Time API. To make this work when we persist and entity we’ll need to add the @EnableJpaAuditing to our Application class.
#4 The @Version can be used by Hibernate to help solve concurrency issues. For each update the version number will be incremented and if we have concurrent updates the first one to finish will be persisted and the other updates will see that they are working on an old version of the entity.
What you’ll see below is the new @SpringBootApplication annotation, which is available since Spring Boot 1.2.0.RC2, which replaces the annotations @Configuration, @ComponentScan and @EnableAutoConfiguration that are usually used for Spring Boot applications.
@SpringBootApplication
@EnableJpaAuditing
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}To work with these entities we’ll add a LinkRepository that extends from the Spring Data JPA interface JpaRepository and implement custom find methods based on the LinkEntity hash and url fields.
public interface LinkRepository extends JpaRepository<LinkEntity, Long> {
public LinkEntity findByHash(String hash);
public LinkEntity findByUrl(String url);
}When you are done doing this, you are doing implementing the database layer including JPA auditing. No EntityManagers, no DataSource configuration, nothing at all. Just add our database driver in the pom.xml, implement a Spring interface and that’s it. Spring Data JPA will expose all our basic CRUD methods automatically because we have implemented the JpaRepository interface. Besides that, we wanted to more specific methods, find by hash and find by URL, this will be generated based on the method names. Since Url and Hash are properties on our LinkEntity, Spring Data JPA will know what SQL we need to implement these queries. Pretty easy right?
REST: Spring Web and business logic
Let us start by implementing the Links REST endpoint and create the POST method that we specified to create a new short link hash. This method will take an URL and store it in the database together with its hash as an LinkEntity. We don’t want to directly call our JPA repository from the REST endpoint, so let us add a LinkService interface which will be the glue between our endpoint and database that contains all the actual business logic that needs to be performed.
public interface LinkService {
LinkEntity create(String url);
}We’ll implement this service in a minute, but let’s create a LinkController first and put it in the be.drissamri.rest package. We will annotate the class with the Spring 4 @RestController class that basically annotates all methods with @ResponseBody to specify that we’ll be returning JSON Objects. We’ll also be using constructor injection to inject for the LinkService that we still need to implement. I tend to prefer constructor injection this because this makes it more flexible when we are writing unit tests. It also makes it very clear which dependencies this class requires when it gets instantiated. If you want to differentiate between optional and required dependencies you can do this by using setter injection for the optional dependencies. This controller is basically just a pass through class, it will barely contain any logic at all, mostly just pass it data to the LinkService and return the correct HTTP Status and objects if needed.
import static org.springframework.http.MediaType.APPLICATION_JSON_VALUE;
import static org.springframework.web.bind.annotation.RequestMethod.*;
@RestController
@RequestMapping(LinkController.LINKS)
public class LinkController {
public static final String LINKS = "/links";
private LinkService linkService;
@Autowired
public LinkController(LinkService linkService) {
this.linkService = linkService;
}
@RequestMapping(method = POST, consumes = APPLICATION_FORM_URLENCODED_VALUE, produces = APPLICATION_JSON_VALUE)
public ResponseEntity<LinkEntity> createShortLink(@RequestParam(value = "url") String longUrl) {
LinkEntity savedLink = linkService.create(longUrl);
return ResponseEntity.ok().body(savedLink);
}
}In general I would never expose my database entities directly to my REST interface, but instead use domain transfer objects (DTO) or something like that to avoid coupling my exposed service with my database layer so both can change separately if needed but for demo purposes I’ll do it like this for now. Next up the more interesting class will be the LinkService, which will contain most of our business logic. First I will check if the requested URL is already in the database by one of the custom find methods we have implemented on the LinkRepository interface, if this is true we’ll just return the LinkEntity in the database. If we don’t have this URL in our database, we’ll create a short Base36 hash from this URL and create a LinkEntity from this hash and the URL. The resulting stored LinkEntity will be returned back to our REST endpoint.
@Service
public class LinkServiceImpl implements LinkService {
private LinkRepository linkRepository;
private HashService shortenService;
@Autowired
public LinkServiceImpl(HashService shortenService, LinkRepository linkRepository) {
this.linkRepository = linkRepository;
this.shortenService = shortenService;
}
@Override
@Transactional
public LinkEntity create(String url) {
LinkEntity resultLink;
LinkEntity existingLink = linkRepository.findByUrl(url);
if (existingLink != null) {
resultLink = existingLink;
} else {
resultLink = createAndSaveLink(url);
}
return resultLink;
}
private LinkEntity createAndSaveLink(String url) {
String hash = shortenService.shorten(url);
LinkEntity requestedLink = new LinkEntity();
requestedLink.setUrl(url);
requestedLink.setHash(hash);
LinkEntity savedLink = linkRepository.save(requestedLink);
return savedLink;
}You can see the logic for the creating the hash is extracted into a separate service since I want to be able to quickly plug another hashing mechanism when needed in the future. If this is needed I can just implement the interface and specify to another bean in this class without the need to change anything in the LinkService at all.
LinkService.java
public interface HashService {
String shorten(String url);
}Base36HashService.java
@Service
public class Base36HashService implements HashService {
private static final int RADIX = 36;
private static final String PIPE = "-";
@Override
public String shorten(String url) {
return encode(url);
}
private String encode(String url) {
if (StringUtils.isEmpty(url)) {
throw new InvalidURLException();
}
boolean isSupportedProtocol = SupportedProtocol.contains(url);
if (!isSupportedProtocol) {
throw new InvalidURLException();
}
String hexValue = Integer.toString(url.hashCode(), RADIX);
if (hexValue.startsWith(PIPE)) {
hexValue = hexValue.substring(1);
}
return hexValue;
}
}I’ve introduced a small support enum which contains the protocols I will support for now, which are http:// and https://.
public enum SupportedProtocol {
HTTP("http"),
HTTPS("https");
private String protocol;
SupportedProtocol(String protocol) {
this.protocol = protocol;
}
public String getProtocol() {
return protocol;
}
public static boolean contains(String protocol) {
boolean isSupported = false;
for (SupportedProtocol validProtocol : SupportedProtocol.values()) {
if (StringUtils.startsWithIgnoreCase(protocol, validProtocol.getProtocol())) {
isSupported = true;
}
}
return isSupported;
}
}At this point we are able to run our Application.java class already to start up an embedded Tomcat. Before we do this I’ll make a quick change to the LinkEntity to avoid exposing fields to our REST client that aren’t necessary. This is easily done by adding an @JsonIgnore annotation to the fields you want to keep hidden. As you could see in the original LinkEntity source code, I already them there to all fields except hash and url. Now we are all set and you can run your application and try it out by doing a POST with your favorite REST client. I use a Chrome extension called Postman.
If you try to do a POST on http://localhost:8080/links?url=http://www.drissamri.com it will return the following response.
{
"url": "http://www.drissamri.com",
"hash": "miufvo"
}That’s our end to end flow for creating a hash. Let’s continue to actually find all persisted links in the database. This will be done by sending a GET request to the same URL. To do this we will extend the LinkService and LinkServiceImpl with an extra find method.
LinkService.java
List<LinkEntity> find();LinkServiceImpl.java
@Override
@Transactional(readOnly = true)
public List<LinkEntity> find() {
List<LinkEntity> foundLinks = linkRepository.findAll();
return foundLinks;
}Like I said before, I wouldn’t recommend exposing your database entities directly to your clients so usually you would want to map your Entity to some sort of Domain Transfer Object (DTO) which only purpose is to transfer data. You might wonder where the findAll() method comes from on the repository since we didn’t implement it on our interface, but this is one of the generated methods you can use by using Spring Data JPA. Awesome right?
Now the final step is to implement the the REST endpoint in the LinkController. We will retrieve all the links and return them to the client together with HTTP 200 OK status.
LinkController.java
@RequestMapping(method = GET, produces = APPLICATION_JSON_VALUE)
public ResponseEntity<List<LinkEntity>> find() {
List<LinkEntity> links = linkService.find();
return ResponseEntity.ok().body(links);
}By doing this you are able to POST an URL’s you want and afterwards find all the links stored in the database by doing a GET to http://localhost:8080/links. That went smooth right.
As a final step let’s create an endpoint that will actually redirect us based on the hash we received. Lets make a RedirectController that is mapped to the root context and only takes a GET method and as a path variable the hash we create. So when we do a GET to http://localhost/{hash} it will redirect us to a corresponding URL stored in the database.
First let us update the LinkService to have a method that can return the Link URL by its corresponding hash.
LinkService.java
String findUrlByHash(String hash);LinkServiceImpl.java
@Override
public String findUrlByHash(String hash) {
String url;
LinkEntity foundLink = linkRepository.findByHash(hash);
if (foundLink == null) {
url = "http://www.drissamri.com"; // Extra traffic, yay!
} else {
url = foundLink.getUrl();
}
return url;
}As a little bonus we’ll redirect everyone that tries to redirect to a unknown hash to my own website, to make it easy. (wohoo!)
Redirecting hash to long URL
We will put this REST endpoint on a new controller, the RedirectController. This time we won’t use the @RestController since we don’t want to send back JSON Objects to the client but just do a redirect for a specific URL. Here we will use the traditional @Controller annotation and map it on the root path of our application. We will only map the GET method and add a path variable that will contain the hash. By using redirect: in the return value, Spring knows will redirect to the given URL.
RedirectController.java
@Controller
@RequestMapping("/")
public class RedirectController {
private LinkService linkService;
@Autowired
public RedirectController(LinkService linkService) {
this.linkService = linkService;
}
@RequestMapping(value = "{hash}", method = RequestMethod.GET)
public String redirect(@PathVariable("hash") String hash) {
return "redirect:" + linkService.findUrlByHash(hash);
}
}Security Considerations
It is important to know that URL shorteners are known to pose an extra security risk, users might try to spread malicious links using your service. One way to try to avoid this is by trying to validate the incoming URL with services like Google Safe Browsing (free), PhishTank (free) and BrightCloud (paid).
Let’s try to add validation to our Linkshortener with Google Safe Browsing and PhishTank because they are free. You should register to get a free API key though, or you’ll be very limited to the amount of requests you can do. You can do this by going to Google Developer Console and/or PhishTank API registration.
You can add the API keys to the application.properties file I have prepared for this application. I left them blank here since I do not want to make my API keys public.
Application.properties
info.build.artifact=${project.artifactId}
info.build.name=@project.name@
info.build.description=@project.description@
info.build.version=@project.version@
### Safe browsing providers ###
# Google Safe Browsing API
provider.google.api=
provider.google.url=https://sb-ssl.google.com/safebrowsing/api/lookup?client={client}&key={apiKey}&appver={appVersion}&pver={apiVersion}&url={url}
provider.google.version=3.1
# PhishTank provider
provider.phishtank.api=
provider.phishtank.url=http://checkurl.phishtank.com/checkurl/Let us start by implementing the Google Safe Browsing API. We’ll make an interface that each URL verifier will have to implement.
public interface UrlVerifier {
public boolean isSafe(String url);
}We have some parameters as you can see in the property file, let’s bundle everything in a configuration class for the Google Verifier.
GoogleSafeBrowsingConfig.java
public class GoogleSafeBrowsingConfig {
private final String PARAMETER_API_KEY = "apiKey";
private final String PARAMETER_API_VERSION = "apiVersion";
private final String PARAMETER_APP_VERSION = "appVersion";
private final String PARAMETER_CLIENT = "client";
private final Map<String, String> parameters;
private String apiUrl;
public GoogleSafeBrowsingConfig(String apiKey,
String apiUrl,
String apiVersion,
String appName,
String appVersion) {
this.parameters = new HashMap<>();
parameters.put(PARAMETER_API_KEY, apiKey);
parameters.put(PARAMETER_API_VERSION, apiVersion);
parameters.put(PARAMETER_APP_VERSION, appVersion);
parameters.put(PARAMETER_CLIENT, appName);
this.apiUrl = apiUrl;
}
public String getApiUrl() {
return apiUrl;
}
public Map<String, String> getParameters() {
return parameters;
}
}Next we’ll actually implement the validation of the URL, this class will use the UrlVerifier interface. We need to do a GET HTTP request to the Google API with certain query parameters as you’ve seen in the property file and configuration class. Spring has the Spring RestTemplate which makes it really easy to do HTTP requests and handle the result. When Google Safe Browsing thinks the URL we send is a phishing or malware site, it will return a HTTP 200 code. When this happens we will return false, meaning the link is unsafe.
public class GoogleSafeBrowsingUrlVerifier implements UrlVerifier {
private static Logger LOGGER = LoggerFactory.getLogger(GoogleSafeBrowsingUrlVerifier.class);
private static final String PARAMETER_URL = "url";
private GoogleSafeBrowsingConfig config;
private RestTemplate restTemplate;
public GoogleSafeBrowsingUrlVerifier(RestTemplate restTemplate, GoogleSafeBrowsingConfig config) {
this.restTemplate = restTemplate;
this.config = config;
}
public boolean isSafe(String url) {
boolean isSafeUrl = true;
Map<String, String> formParameters = config.getParameters();
formParameters.put(PARAMETER_URL, url);
try {
ResponseEntity<String> response = restTemplate.getForEntity(config.getApiUrl(), String.class, formParameters);
LOGGER.debug("Google Safe Browsing API returned HTTP Status: {} and message: {}", response.getStatusCode(), response.getBody());
if (response.getStatusCode() == HttpStatus.OK) {
LOGGER.debug("Possible unsafe link: {} - {}", url, response.getBody());
isSafeUrl = false;
}
} catch (RestClientException restException) {
LOGGER.warn("Exception occurred during HTTP call to Google Safe Browsing API: {}", restException);
}
return isSafeUrl;
}
}Now we will do the same for the PhishTank API. We will make another configuration class to hold all the necessary properties.
public class PhishTankConfig {
private final String PARAMETER_API_KEY = "app_key";
private final String PARAMETER_FORMAT = "format";
private final String RESPONSE_FORMAT = "json";
private final String apiUrl;
private final MultiValueMap<String, String> parameters;
public PhishTankConfig(String apiKey, String apiUrl) {
this.apiUrl = apiUrl;
this.parameters = new LinkedMultiValueMap<>();
parameters.add(PARAMETER_API_KEY, apiKey);
parameters.add(PARAMETER_FORMAT, RESPONSE_FORMAT);
}
public String getApiUrl() {
return apiUrl;
}
public MultiValueMap<String, String> getParameters() {
return parameters;
}
}The PhishTank API works a little bit different since we’ll need to do a HTTP POST, with form parameters instead of query parameters. The API will send back HTTP 200 and we’ll need to check the JSON body response to see if the service thinks the URL is malicious or not. We’ll only be checking one value in the JSON response, which is a boolean in_database. This boolean will tell us if the service knows this URL, which means it is submitted as a phishing link. This doesn’t mean it is actually verified already, so if we were to use this service we’d probably want to parse the response and take into account more properties from the result. The service could also send back HTTP 509 meaning that we have made too many requests, but we’ll take this and any other error response codes and just log a warning in the log files. When this happens, we will skip the verification and accept the link as safe for now.
To parse out the in_database fields in the JSON response, I’ve added the JSON Path library to the POM. This library makes it easy to query JSON like we would use XPath for XML documents.
pom.xml
<dependency>
<groupId>com.jayway.jsonpath</groupId>
<artifactId>json-path</artifactId>
<version>${json-path.version}</version>
</dependency>Then we are set to actually implement the PhishTank URL verifier.
PhishTankUrlVerifier.java
public class PhishTankUrlVerifier implements UrlVerifier {
private static Logger LOGGER = LoggerFactory.getLogger(GoogleSafeBrowsingUrlVerifier.class);
private static final String PARAMETER_URL = "url";
private static final String IN_DATABASE_PARSE_EXPRESSION = "results.in_database";
private RestTemplate restTemplate;
private PhishTankConfig config;
public PhishTankUrlVerifier(RestTemplate restTemplate, PhishTankConfig config) {
this.restTemplate = restTemplate;
this.config = config;
}
@Override
public boolean isSafe(String url) {
boolean isSafeUrl = true;
try {
MultiValueMap<String, String> formParameters = config.getParameters();
formParameters.add(PARAMETER_URL, url);
ResponseEntity<String> response = restTemplate.postForEntity(config.getApiUrl(), formParameters, String.class);
if (response.getStatusCode() == HttpStatus.OK) {
boolean isPhishingUrl = JsonPath.parse(response.getBody()).read(IN_DATABASE_PARSE_EXPRESSION);
if (isPhishingUrl) {
isSafeUrl = false;
}
} else {
LOGGER.warn("Request for PhishTank API failed with status: {} - : {}", response.getStatusCode(), response);
}
} catch (RestClientException | PathNotFoundException exception) {
LOGGER.warn("Something went wrong while processing PhishTank API: {}", exception);
}
return isSafeUrl;
}
}Now we have two different URL verifiers, we want to use both of them for each request. Since we both implement the same UrlVerifier interface, if we make them Spring beans we can Autowire a List of the interface. We will do this in a seperate class that will loop over this List, so we can in the future add more verifiers if we would want to and it will check each one in the list to see if the URL we want to shorten is not a malicious link. The two URL Verifiers we have implemented both expect the URL to be encoded, so we’ll do this here as well.
UrlVerifiers.java
@Component
public class UrlVerifiers {
private static final String ENCODING_UTF8 = "UTF-8";
private List<UrlVerifier> urlVerifiers;
@Autowired
public UrlVerifiers(List<UrlVerifier> urlVerifiers) {
this.urlVerifiers = urlVerifiers;
}
public boolean isSafe(String url) {
boolean isValid = true;
String encodedUrl;
try {
encodedUrl = URLEncoder.encode(url, ENCODING_UTF8);
} catch (UnsupportedEncodingException e) {
throw new LinkshortenerException("Unable to encode to UTF-8", e);
}
for (UrlVerifier verifier : urlVerifiers) {
if (verifier != null) {
boolean isValidByProvider = verifier.isSafe(encodedUrl);
if (!isValidByProvider) {
isValid = false;
}
}
}
return isValid;
}
}Now you might wonder, how can we Autowire the UrlVerifier if they are not annotated with @Component or something else? You are right, I’m running a bit ahead of my self. I still have to show you the last class to complete this section. We have a seperate @Configuration class that will wire the different UrlVerifiers and also the RestTemplate we have used to make the HTTP requests.
@Configuration
public class ServiceConfig {
@Value("${provider.google.api}") private String googleApiKey;
@Value("${provider.google.url}") private String googleApiUrl;
@Value("${provider.google.version}") private String googleApiVersion;
@Value("${provider.phishtank.url}") private String phishtankApiUrl;
@Value("${provider.phishtank.api}") private String phishtankApiKey;
@Value("${info.build.name}") private String appName;
@Value("${info.build.version}") private String appVersion;
@Bean
public UrlVerifier googleSafetyProvider() {
UrlVerifier googleUrlVerifier = null;
if (!StringUtils.isEmpty(googleApiKey)) {
GoogleSafeBrowsingConfig config = new GoogleSafeBrowsingConfig(googleApiKey, googleApiUrl, googleApiVersion, appName, appVersion);
googleUrlVerifier = new GoogleSafeBrowsingUrlVerifier(restTemplate(), config);
}
return googleUrlVerifier;
}
@Bean
public UrlVerifier phishTankVerifier() {
UrlVerifier phishTankVerifier = null;
if (!StringUtils.isEmpty(phishtankApiKey)) {
PhishTankConfig config = new PhishTankConfig(phishtankApiKey, phishtankApiKey);
phishTankVerifier = new PhishTankUrlVerifier(restTemplate(), config);
}
return phishTankVerifier;
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}You see we first check if the API key for each of the services is populated in the application.properties file, if that is not the case we will not create the UrlVerifier. If we want to add a new verifier in the future we just add another bean in this configuration file and make sure it implements the UrlVerifier interface and it will automatically be added to the list of verifiers that will be processed.
Great success
Tadaa! A very simple Linkshortener REST API. In the source code you’ll see we also implement a DELETE method, but this is pretty straight forward that I didn’t go into it here. You can take a look at the full source code at the GitHub repository.